데이터 오픈마켓
국가교통 데이터 오픈마켓에서 제공하고 있는 서비스를 메뉴얼을 통해 확인해보세요.
flowchart LR A-.->B;
시작하기
1단계) 데이터 오픈마켓 접속

데이터 오픈마켓을 이용하기 위해서는 사이트 상단의 회원가입을 통해 이용할 수 있습니다.
2단계) 회원가입

회원가입은 네이버, 구글 아이디를 통한 간편 가입 및 이메일/문자 인증을 통한 가입이 가능합니다.
데이터 상품 구매
데이터를 활용하기 위해서는 우선 데이터 구매하여야 합니다. 구매 후 데이터를 다운받아 보세요.
1단계) 데이터 검색

홈페이지 상단에 데이터 상품 → 데이터 검색을 클릭합니다.
2단계) 상품 선택

① 검색조건 - 찾고자 하는 카테고리, 기업 등의 조건을 통해 데이터를 쉽게 찾을 수 있습니다.
② 외부 데이터 - 빅데이터 플랫폼에 있는 다른 데이터도 함께 확인할 수 있습니다.
③ 데이터 상품 - 구매하고자 하는 데이터 상품을 클릭하면 상품 구매로 넘어갑니다.
3단계) 상품 구매

① 상품 구매 및 요약 - 선택한 상품의 간단한 요약 정보를 제공해주며 상품 구매 버튼을 눌러 상품 구매를 할 수 있습니다.
② 상품 설명 - 상품에 대한 상세한 설명(판매업체, 등록일자, 주기, 용량 등)을 확인할 수 있습니다.
③ 샘플 데이터 - csv 파일의 경우 테이블 형태로 샘플 데이터 모습을 보여주고 데이터 정의서를 통해 데이터 구조를 제공합니다.
4단계) 데이터 구매

구매할 데이터를 선택 후 선택 구매하기 버튼을 눌러주세요.

활용목적 및 구매조건을 확인 한 후 결제를 진행하시면 됩니다.

결제가 완료된 데이터는 나의 구매내역에서 다운로드 받으실 수 있습니다.
데이터 경진대회
국가교통 데이터 오픈마켓에서는 국토교통 데이터 경진대회 등의 공모전을 개최하고 있습니다.
공모전에 참여하거나 직접 공모전을 개최할 수 있습니다.
공모전 개최
1단계) 회원 가입
- 오픈마켓 회원가입을 합니다.
교통데이터 오픈마켓 회원이면 누구나 무료로 공모전을 등록하실 수 있습니다.
2단계) 공모전 등록 및 승인요청
- 공모전 등록 메뉴에서 공모전 개요를 작성해서 오픈마켓 관리자에게
승인 요청 합니다.
(공모명, 주최 사, 공모기간, 공모전지원 요강 등)
3단계) 공모전 검토 및 진행
- 제출된 공모전 요강을 확인하고 담당자와 협의하여 공모전을 승인하면,
공모전 페이지를 오픈합니다.
(공모전 내용 확인을 위해 공모전 담당자에게 연락 드려 상세히 협의 진행)
4단계) 공모전 운영
- 교통데이터 오픈마켓은 마켓회원 대상으로 등록된 공모전 참여를 독려하여
성공적인 공모전 운영을 지원합니다.
(회원 SMS 및 이메일 발송, 메인 배너 홍보 등)
5단계) 공모전 종료
- 공모전 참가자에 대한 평가를 지원하고 선정 결과를 공모전 페이지에 제공하고 종료합니다.
 →
→  →
→  →
→  →
→ 
공모전 참여
1단계) 공모전 선택

공모전 현황을 확인하고 참가할 공모전을 선택합니다.
2단계) 공모전 확인

공모전의 주제, 참가에 관한 요강을 확인해주세요.
3단계) 공모전 참여

공모전에 참가하고 자료를 제출합니다.
4단계) 공모전 결과발표

공모전 결과는 전문가의 심사를 거쳐 홈페이지에 게재됩니다.
참고) 공모전 Q/A

공모전 관련 문의사항이 있으면 언제나 문의해주세요.
데이터 활용사례
데이터를 어떻게 활용하는지 어떤 가치가 있는지 확인해보세요.
다양한 기업이나 공공기관에서 데이터를 활용하여 정책이나 사업을 추진하고 있어요.
활용사례

예시

데이터를 활용한 각 기관의 활용사례를 확인해보세요.
리빙랩

한국교통연구원에서 제공하는 리빙랩을 활용하여 교통 정보를 분석하고 다양한 API를 활용해보세요.
참고) 보육교육 교통정보 시각화

데이터 오픈마켓에는 보육교육 시설의 교통정보를 시각화하여 어린이 보호구역에 대한 어린이, 청소년의 안전을 진단하고 정책 수립에 활용할 수 있습니다.
참고) 서울 버스정류장 시각화

서울시 버스정류장의 위치정보 시각화를 확인해보세요.
내 정보관리
나의 회원정보를 수정하거나 구매내역, 문의내역을 확인할 수 있습니다.
안심구역 신청을 통해 오프라인 안심구역에 방문하여 가명정보 등 민감 데이터의 사용도 가능합니다.
나의 구매내역

내가 구매한 데이터를 확인하고 다운로드 받을 수 있습니다. API의 경우 호출할 수 있는 예제도 제공됩니다.
나의 문의내역

오픈마켓 내에서 문의한 데이터, Q/A 등의 문의내역을 확인할 수 있습니다.
나의 안심구역

안심구역 신청 및 신청현황 확인을 통해 승인된 사용자의 안심구역 이용이 가능합니다.
개인정보 관리

개인정보를 수정하고 업데이트 할 수 있습니다.
판매회원 전환

구매회원은 언제든지 사업자 등록증 등을 통해 데이터를 판매할 수 있습니다.
관심데이터 관리

메인화면에서 내가 구매하고자하는 키워드의 데이터를 확인할 수 있습니다.
고객센터
고객센터에는 공지사항, FAQ, Q/A, 데이터 신청 및 문의 등 전반적인 사이트 이용에 도움이 되거나 불편사항 등을 건의할 수 있는 공간입니다.
공지사항

공지사항에는 각종 공모전 개최계획, 새로운 데이터 제공 계획 등을 확인하실 수 있습니다.
FAQ

FAQ는 자주 묻는 질문들을 모아놓았습니다. Q/A에 질의하기 전에 먼저 확인해주세요.
Q/A

데이터 및 사이트 이용에 있어서 불편사항을 문의할 수 있고 건의도 가능합니다.
데이터 신청 및 문의

데이터 관련 전용 게시판입니다. 신규 데이터의 신청 및 문의사항을 올려주세요.
데이터 안심구역
국가교통 데이터 안심구역은 국토교통 분야의 민감 데이터를 오프라인 안심구역을 통해 활용할 수 있습니다.
시작하기
데이터 안심구역에 방문하기 전에 오픈마켓에서 활용할 데이터를 신청해주세요.
1단계) 데이터 검색

홈페이지 상단에 데이터 상품 → 데이터 검색을 클릭합니다.
2단계) 데이터 선택

데이터를 확인 후 안심구역 신청 버튼을 누릅니다.

신청이 완료되었단 화면이 나오면 안심구역 데이터 신청이 완료된 것입니다.
3단계) 안심구역 신청

안심구역에서 활용할 데이터를 선택 후 안심구역 신청 버튼을 누릅니다.

보안 서약서 및 방문일자 등을 기입한 후 이용신청을 완료합니다.
4단계) 신청현황 확인

방문신청 일자 및 신청상태를 확인합니다. 방문승인이 완료되면 안심구역 이용이 가능합니다.

안심구역에 있는 분석 시스템을 통해 데이터를 분석 및 활용합니다.
데이터 분석/시각화 따라하기
데이터 분석 및 시각화를 따라해보세요.
공간자기상관성 분석
개요
-
공간데이터(Spatial data)들은 순수한 자신만의 정보를 가지고 있을 뿐만 아니라, 지리적(geographical space)에 관한 정보를 함께 포함하고 있다. 이러한 공간데이터를 분석하기 위하여 기존의 많은 선형모델들을 적용하여 해석하려고 했으나, ‘공간’이라는 요인을 고려하지 못하여 의미있는 분석결과를 도출하지 못하였다.
-
Doreian(1981)에 따르면 “변수들이 무작위적이고 오류항이 독립적이며 동일한 분포를 갖는 다는 가정을 하는 전통적인 선형분석 방법들로 공간준거 데이터(spatially-referenced data)를 분석할 경우 많은 사회경제현상, 인구현상 및 자연현상(natural phenomena)이 공간상에서 나타나는 특성인 의존성(spatial dependence) 및 상호작용(spatial interaction)을 통제하지 못한다.”고 하였다.
-
Tober의 지리의 제1법칙(the first law of geography) - Everything is realted everything else, but near things are more related than distant things. 에서와 같이 공간상의 객체들은 공간상에 무작위(random)하게 있지 않고 서로간에 영향을 주고받으며 존재한다고 할 수 있다.
-
이와 같이 지리적 공간상에서 공간객체간의 상호의존성과 상호작용을 공간적자기상관(spatial autocorrelation)이라고 할 수 있다.
-
Anselin and Bera(1998)는 “공간상에 분포하는 공간객체들은 위치의 유사성이 높아짐에 따라 객체들이 갖는 값의 유사성도 높아가는 현상”이라고 정의하기도 하였다.
-
공간적자기상관에는 ’정적 공간자기상관(positive spatial autocorrelation)’과 ’부적 공간자기상관(negative spatial autocorrelation)’이 있다. 정적 공간자기상관은 공간실체들이 서로 유사한 값을 갖으며 군집적으로 분포하는 경우이며, 반대로 부적 공간자기상관은 공간실체들이 서로 상이한 값들을 갖으며 군집적으로 분포하는 경우이다.
분석 데이터
- 행정동 단위의 모든 데이터에 적용 가능
- Ex: 행정동별 교통, 유동인구, 범죄 데이터 등
- 현재 MBD 데이터는 불완전하기 때문에 행정동 별 임의의 데이터를 대상으로 분석 노트북을 작성하였음
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import geopandas as gpd
shp_link = "AL_00_D001_20200106(EMD).shp"
import sys
import os
sys.path.append(os.path.abspath('..'))
from pysal.explore import esda
import pandas as pd
import geopandas as gpd
import pysal.lib as lps
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
df = gpd.read_file('AL_00_D001_20200106(EMD).shp', encoding="euckr")
df.head()
| A0 | A1 | A2 | A3 | geometry | |
|---|---|---|---|---|---|
| 0 | 295 | 11110140 | 삼청동 | 2019-02-21 | POLYGON ((197597.735 454551.233, 197599.083 45… |
| 1 | 296 | 11110101 | 청운동 | 2019-02-21 | POLYGON ((196524.180 453809.271, 196541.748 45… |
| 2 | 297 | 11110168 | 동숭동 | 2019-02-21 | POLYGON ((200515.600 453698.981, 200521.372 45… |
| 3 | 315 | 11110166 | 연건동 | 2019-02-21 | POLYGON ((199711.309 453300.989, 199718.145 45… |
| 4 | 316 | 11110105 | 창성동 | 2019-02-21 | POLYGON ((197592.504 453280.724, 197592.907 45… |
df.columns
Index([‘A0’, ‘A1’, ‘A2’, ‘A3’, ‘geometry’], dtype=‘object’)
df['A0'].describe()
count 5079.000000 mean 2251.962985 std 5697.271617 min 3.000000 25% 120.000000 50% 381.000000 75% 1329.000000 max 61906.000000 Name: A0, dtype: float64
ax = df.plot(figsize=(11, 11), color="w", edgecolor="k")
#ax.set_title("South Korea")
ax.set_axis_off()
plt.show()

Similarity
wq = lps.weights.Queen.from_dataframe(df)
wq.transform = 'r'
(’WARNING: ‘, 539, ’ is an island (no neighbors)’) (’WARNING: ‘, 663, ’ is an island (no neighbors)’) (’WARNING: ‘, 705, ’ is an island (no neighbors)’) (’WARNING: ‘, 718, ’ is an island (no neighbors)’) (’WARNING: ‘, 719, ’ is an island (no neighbors)’) (’WARNING: ‘, 725, ’ is an island (no neighbors)’) (’WARNING: ‘, 726, ’ is an island (no neighbors)’) (’WARNING: ‘, 735, ’ is an island (no neighbors)’) (’WARNING: ‘, 745, ’ is an island (no neighbors)’) (’WARNING: ‘, 746, ’ is an island (no neighbors)’) (’WARNING: ‘, 747, ’ is an island (no neighbors)’) (’WARNING: ‘, 748, ’ is an island (no neighbors)’) (’WARNING: ‘, 749, ’ is an island (no neighbors)’) (’WARNING: ‘, 919, ’ is an island (no neighbors)’) (’WARNING: ‘, 953, ’ is an island (no neighbors)’) (’WARNING: ‘, 1472, ’ is an island (no neighbors)’) (’WARNING: ‘, 1653, ’ is an island (no neighbors)’) (’WARNING: ‘, 1778, ’ is an island (no neighbors)’) (’WARNING: ‘, 2001, ’ is an island (no neighbors)’) (’WARNING: ‘, 2364, ’ is an island (no neighbors)’) (’WARNING: ‘, 2864, ’ is an island (no neighbors)’) (’WARNING: ‘, 3057, ’ is an island (no neighbors)’) (’WARNING: ‘, 3140, ’ is an island (no neighbors)’) (’WARNING: ‘, 3213, ’ is an island (no neighbors)’) (’WARNING: ‘, 3308, ’ is an island (no neighbors)’) (’WARNING: ‘, 3337, ’ is an island (no neighbors)’) (’WARNING: ‘, 3400, ’ is an island (no neighbors)’) (’WARNING: ‘, 3597, ’ is an island (no neighbors)’) (’WARNING: ‘, 3769, ’ is an island (no neighbors)’) (’WARNING: ‘, 4000, ’ is an island (no neighbors)’) (’WARNING: ‘, 4251, ’ is an island (no neighbors)’) (’WARNING: ‘, 4327, ’ is an island (no neighbors)’) (’WARNING: ‘, 4328, ’ is an island (no neighbors)’) (’WARNING: ‘, 4329, ’ is an island (no neighbors)’) (’WARNING: ‘, 4330, ’ is an island (no neighbors)’) (’WARNING: ‘, 4331, ’ is an island (no neighbors)’) (’WARNING: ‘, 4333, ’ is an island (no neighbors)’) (’WARNING: ‘, 4334, ’ is an island (no neighbors)’) (’WARNING: ‘, 4336, ’ is an island (no neighbors)’) (’WARNING: ‘, 4337, ’ is an island (no neighbors)’) (’WARNING: ‘, 4338, ’ is an island (no neighbors)’) (’WARNING: ‘, 4341, ’ is an island (no neighbors)’) (’WARNING: ‘, 4346, ’ is an island (no neighbors)’) (’WARNING: ‘, 4347, ’ is an island (no neighbors)’) (’WARNING: ‘, 4362, ’ is an island (no neighbors)’) (’WARNING: ‘, 4372, ’ is an island (no neighbors)’) (’WARNING: ‘, 4373, ’ is an island (no neighbors)’) (’WARNING: ‘, 4379, ’ is an island (no neighbors)’) (’WARNING: ‘, 4380, ’ is an island (no neighbors)’) (’WARNING: ‘, 4381, ’ is an island (no neighbors)’) (’WARNING: ‘, 4382, ’ is an island (no neighbors)’) (’WARNING: ‘, 4383, ’ is an island (no neighbors)’) (’WARNING: ‘, 4384, ’ is an island (no neighbors)’) (’WARNING: ‘, 4385, ’ is an island (no neighbors)’) (’WARNING: ‘, 4386, ’ is an island (no neighbors)’) (’WARNING: ‘, 4474, ’ is an island (no neighbors)’) (’WARNING: ‘, 4542, ’ is an island (no neighbors)’) (’WARNING: ‘, 4567, ’ is an island (no neighbors)’) (’WARNING: ‘, 4629, ’ is an island (no neighbors)’) (’WARNING: ‘, 4637, ’ is an island (no neighbors)’) (’WARNING: ‘, 4703, ’ is an island (no neighbors)’) (’WARNING: ‘, 4856, ’ is an island (no neighbors)’) (’WARNING: ‘, 5061, ’ is an island (no neighbors)’) (’WARNING: ‘, 5062, ’ is an island (no neighbors)’)
Moran’s I
- 전체연구지역의 공간적자기상관 관계를 하나의 값으로 보여주는 글로벌 지수(global index)이다.
- 공간적자기상관을 파악하기 위한 유용한 측정척도로, 인접해 있는 공간단위 (neighboring spatial units)들이 갖는 값(values)을 비교하여 이 계수를 산출하게 된다.
- 만일 인접한 공간단위들이 ’전체 연구지역(entire study area)’에 걸쳐 유사한 값을 갖는 경우, Moran I 계수는 높은 ’정적 공간상관’을 갖는 반면, 인접한 공간 단위들이 서로 상이한 값들을 갖게 되면 Moran I 계수는 높은 ’부적 공간상관’을 갖게 된다.
y = df['A0']
np.random.seed(12345)
mi = esda.moran.Moran(y, wq)
mi.I
0.6087514418350501
- A positive z-value: data is spatially clustered in some way.
- A negative z-value: data is clustered in a competitive way. For example, high values may be repelling high values or negative values may be repelling negative values.
mi.p_sim
0.001
fig, ax = plt.subplots(figsize=(12,10), subplot_kw={'aspect':'equal'})
df.plot(column='A0', scheme='Quantiles', k=5, cmap='GnBu', legend=True, ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x2a362e202c8>

Anselin Local Morans’ I (LISA)
- 연구지역내에서 발생할 수 있는 공간적자기상관의 국지적 변이(local variatons)를 고려한 시각적 지표이다
- LISA를 이용하면 한 변수의 공간적자기상관이 특정 지역에서 높게 나타나는 ’Hot spot’을 찾을 수 있다.
- 국지적인 규모에서 공간자기상관 정도를 측정하기 위해서는, 각각의 공간단위(each areal unit)에서 공간자기상관 값이 계산되어야 하는데 여러 LISA중 가장 손쉽게 활용될 수 있는 것은 ’국지 Moran (local Moran)’이다.
Moran Scatterplot
np.random.seed(12345)
wq.transform = 'r'
lag_price = lps.weights.lag_spatial(wq, df['A0'])
price = df['A0']
b, a = np.polyfit(price, lag_price, 1)
f, ax = plt.subplots(1, figsize=(9, 9))
plt.plot(price, lag_price, '.', color='firebrick')
# dashed vert at mean of the price
plt.vlines(price.mean(), lag_price.min(), lag_price.max(), linestyle='--')
# dashed horizontal at mean of lagged price
plt.hlines(lag_price.mean(), price.min(), price.max(), linestyle='--')
# red line of best fit using global I as slope
plt.plot(price, a + b*price, 'r')
plt.title('Moran Scatterplot')
plt.ylabel('Spatial Lag of Value')
plt.xlabel('Value')
plt.show()

- The upper-right quadrant and the lower-left quadrant correspond with positive spatial autocorrelation (similar values at neighboring locations).
- We refer to them as respectively high-high and low-low spatial autocorrelation.
- In contrast, the lower-right and upper-left quadrant correspond to negative spatial autocorrelation (dissimilar values at neighboring locations).
- We refer to them as respectively high-low and low-high spatial autocorrelation.
LISA
li = esda.moran.Moran_Local(y, wq)
li.q
array([3, 3, 3, …, 3, 3, 3])
(li.p_sim < 0.05).sum()
1671
sig = li.p_sim < 0.05
hotspot = sig * li.q==1
coldspot = sig * li.q==3
doughnut = sig * li.q==2
diamond = sig * li.q==4
spots = ['n.sig.', 'hot spot']
labels = [spots[i] for i in hotspot*1]
df = df
from matplotlib import colors
hmap = colors.ListedColormap(['red', 'lightgrey'])
f, ax = plt.subplots(1, figsize=(9, 9))
df.assign(cl=labels).plot(column='cl', categorical=True, \
k=2, cmap=hmap, linewidth=0.1, ax=ax, \
edgecolor='white', legend=True)
ax.set_axis_off()
plt.show()

spots = ['n.sig.', 'cold spot']
labels = [spots[i] for i in coldspot*1]
df = df
from matplotlib import colors
hmap = colors.ListedColormap(['blue', 'lightgrey'])
f, ax = plt.subplots(1, figsize=(9, 9))
df.assign(cl=labels).plot(column='cl', categorical=True, \
k=2, cmap=hmap, linewidth=0.1, ax=ax, \
edgecolor='white', legend=True)
ax.set_axis_off()
plt.show()

spots = ['n.sig.', 'doughnut']
labels = [spots[i] for i in doughnut*1]
df = df
from matplotlib import colors
hmap = colors.ListedColormap(['lightblue', 'lightgrey'])
f, ax = plt.subplots(1, figsize=(9, 9))
df.assign(cl=labels).plot(column='cl', categorical=True, \
k=2, cmap=hmap, linewidth=0.1, ax=ax, \
edgecolor='white', legend=True)
ax.set_axis_off()
plt.show()

spots = ['n.sig.', 'diamond']
labels = [spots[i] for i in diamond*1]
df = df
from matplotlib import colors
hmap = colors.ListedColormap(['pink', 'lightgrey'])
f, ax = plt.subplots(1, figsize=(9, 9))
df.assign(cl=labels).plot(column='cl', categorical=True, \
k=2, cmap=hmap, linewidth=0.1, ax=ax, \
edgecolor='white', legend=True)
ax.set_axis_off()
plt.show()

sig = 1 * (li.p_sim < 0.05)
hotspot = 1 * (sig * li.q==1)
coldspot = 3 * (sig * li.q==3)
doughnut = 2 * (sig * li.q==2)
diamond = 4 * (sig * li.q==4)
spots = hotspot + coldspot + doughnut + diamond
spots
array([3, 0, 0, …, 3, 0, 0])
spot_labels = [ '0 ns', '1 hot spot', '2 doughnut', '3 cold spot', '4 diamond']
labels = [spot_labels[i] for i in spots]
from matplotlib import colors
hmap = colors.ListedColormap([ 'lightgrey', 'red', 'lightblue', 'blue', 'pink'])
f, ax = plt.subplots(1, figsize=(9, 9))
df.assign(cl=labels).plot(column='cl', categorical=True, \
k=2, cmap=hmap, linewidth=0.1, ax=ax, \
edgecolor='white', legend=True)
ax.set_axis_off()
plt.show()

Reference
공간자기상관성 관련 설명자료:
- 이경주, 황명화, 한선희, & 양은정. (2015). 공간통계 분석의 이해와 활용을 위한 첫걸음.
참고자료:
-
Andresen, M. A. (2011). Estimating the probability of local crime clusters: The impact of immediate spatial neighbors. Journal of Criminal Justice, 39(5), 394-404.
-
Suthanaya, P. A. (2011). Spatial Autocorrelation Analyses of the Commuting Preferences by Bus in the Sydney Metropolitan Region. Journal of Civil Engineering, 18(1), 71-80.
-
Truong, L. T., & Somenahalli, S. V. (2011). Using GIS to identify pedestrian-vehicle crash hot spots and unsafe bus stops. Journal of Public Transportation, 14(1), 6.
-
Tselios, V. (2008). Income and educational inequalities in the regions of the European Union: geographical spillovers under welfare state restrictions. Papers in Regional Science, 87(3), 403-430.
-
Yun, J. M., & Choi, D. J. (2015). Geographically weighted regression on the characteristics of land use and spatial patterns of floating population in seoul city. Journal of Korean Society for Geospatial Information System, 23(3), 77-84.
-
김현중, & 이성우. (2013). 범죄발생의 공간의존성 변화와 핫스팟 분포, 2001-2010. 주거환경, 11(2), 27-41.
-
이연수, 진창종, & 추상호. (2012). 공간계량분석을 이용한 대중교통 이용에 영향을 미치는 공간적 특성요인 분석에 관한 연구: 서울시 행정동을 중심으로. 서울도시연구, 13(4), 97-111.
광역철도 수송 데이터 탐색적 분석 및 시각화
개요
- 운행일자를 기준으로 2019년 10월 한 달 간 운행열차의 운행내역 데이터를 사용하여 정차역에 따른 승,하차,통과 인원 및 해당 역 별 지가지수를 파악하여 광역 철도 데이터의 탐색적 분석 및 공간 데이터 시각화 분석이 이루어짐.
분석 데이터
- 일자별전철역승차인원 데이터
- 여객역코드 데이터
- 역 별 위치 데이터(위,경도)
- 역세권 별 지가지수 데이터(2014~2017)
load python library
import pandas as pd
import pandas_profiling
pd.options.mode.chained_assignment = None
from pyproj import Proj, transform
import numpy as np
import matplotlib.pyplot as plt
import ipywidgets as widgets
from ipywidgets import interact, interact_manual, GridspecLayout
import ipywidgets
from collections import OrderedDict
import geopandas as gpd
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import warnings
warnings.filterwarnings(action='ignore')
load dataset
path = '/home/yubin90/pyWork/diamond/'
def stp_cols(df):
cols = list(map(str.strip, df.columns.tolist()))
df.columns = cols
return df
ride_acvm_df = pd.read_csv(path+'TB_COL_KR_TRVL_STNP_CLSF_RIDE_ACVM.csv', low_memory=False)
ride_acvm_df = stp_cols(ride_acvm_df)
ride_acvm_df = ride_acvm_df.drop(labels='AGGR_YMDHMS', axis=1)
trvl_stn_cd_df = pd.read_csv(path+'TB_COL_KR_TRVL_STN_CD.csv', low_memory=False)
trvl_stn_cd_df = stp_cols(trvl_stn_cd_df)
trvl_stn_cd_df = trvl_stn_cd_df.drop(labels='AGGR_YMDHMS', axis=1)
trvl_stn_cd_df = trvl_stn_cd_df.drop_duplicates(subset='STN_CD')
stn_loc_df = pd.read_csv(path+'stn_loc_no_dup.csv', encoding='cp949')
code mapping
#년월 생성
ride_acvm_df['YYMM'] = ride_acvm_df['RUN_DT'].astype(str).str[:-2]
# 역명코드 dict 생성
trvl_stn_cd_dict= dict(zip(trvl_stn_cd_df.STN_CD, trvl_stn_cd_df.KOR_STN_NM))
# dict mapping(역명 한글이름 매칭)
ride_acvm_df['KOR_STOP_STN'] = ride_acvm_df['STOP_STN'].map(trvl_stn_cd_dict)
역 위치 (위,경도) 매핑
ride_acvm_with_loc = pd.merge(ride_acvm_df,stn_loc_df, how='left', left_on='KOR_STOP_STN', right_on='STN_NM')
ride_acvm_with_loc
| RUN_DT | STOP_STN | STLB_TRN_CLSF_CD | UP_DN_DV_CD | ABRD_PRNB | GOFF_PRNB | NSTP_PRNB | YYMM | KOR_STOP_STN | STN_NM | LAT | LNG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20191001 | 3900280 | 0 | D | 1148 | 3021 | 15849 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 |
| 1 | 20191001 | 3900280 | 7 | D | 630 | 1422 | 6902 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 |
| 2 | 20191001 | 3900280 | 10 | D | 49 | 127 | 615 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 |
| 3 | 20191001 | 3900023 | 7 | U | 19 | 4749 | 378 | 201910 | 서울 | 서울 | 37.554073 | 126.970702 |
| 4 | 20191001 | 3900096 | 7 | U | 1332 | 710 | 4545 | 201910 | 동대구 | 동대구 | 35.879437 | 128.628784 |
| … | … | … | … | … | … | … | … | … | … | … | … | … |
| 29277 | 20191031 | 3900292 | 1 | U | 10 | 6 | 60 | 201910 | 충주 | 충주 | 36.975892 | 127.909136 |
| 29278 | 20191031 | 3900556 | 1 | U | 0 | 0 | 41 | 201910 | 춘양 | 춘양 | 36.937810 | 128.919938 |
| 29279 | 20191031 | 3900611 | 1 | U | 5 | 0 | 36 | 201910 | 민둥산 | 민둥산 | 37.243701 | 128.773657 |
| 29280 | 20191031 | 3900703 | 1 | D | 0 | 1 | 61 | 201910 | 북천 | 북천 | 35.111383 | 127.883501 |
| 29281 | 20191031 | 3900703 | 1 | U | 0 | 0 | 39 | 201910 | 북천 | 북천 | 35.111383 | 127.883501 |
29282 rows × 12 columns
역 별 승,하차, 통과 인원 수 상위 10
for_top_df = ride_acvm_df[['ABRD_PRNB', 'GOFF_PRNB', 'NSTP_PRNB', 'KOR_STOP_STN']]
#승차 top 10
sum_abrd_by_stn = pd.DataFrame(for_top_df.groupby('KOR_STOP_STN')['ABRD_PRNB'].sum())
sum_abrd_by_stn = sum_abrd_by_stn[sum_abrd_by_stn.index != '청량리']
sum_abrd_by_stn.sort_values('ABRD_PRNB', ascending=False).head(10)
| ABRD_PRNB | |
|---|---|
| KOR_STOP_STN | |
| — | — |
| 서울 | 1527592 |
| 동대구 | 748905 |
| 용산 | 720647 |
| 대전 | 654794 |
| 부산 | 636205 |
| 수원 | 503330 |
| 광명 | 422479 |
| 영등포 | 358667 |
| 오송 | 270318 |
| 천안아산 | 250665 |
#하차 top 10
sum_goff_by_stn = pd.DataFrame(for_top_df.groupby('KOR_STOP_STN')['GOFF_PRNB'].sum())
sum_goff_by_stn.sort_values('GOFF_PRNB', ascending=False).head(10)
| GOFF_PRNB | |
|---|---|
| KOR_STOP_STN | |
| — | — |
| 서울 | 1545800 |
| 동대구 | 754050 |
| 용산 | 722747 |
| 대전 | 656247 |
| 부산 | 632395 |
| 수원 | 508386 |
| 광명 | 416549 |
| 영등포 | 362172 |
| 청량리 | 277838 |
| 오송 | 261490 |
#통과 top 10
sum_nstp_by_stn = pd.DataFrame(for_top_df.groupby('KOR_STOP_STN')['NSTP_PRNB'].sum())
sum_nstp_by_stn.sort_values('NSTP_PRNB', ascending=False).head(10)
| NSTP_PRNB | |
|---|---|
| KOR_STOP_STN | |
| — | — |
| 대전 | 3271135 |
| 광명 | 3027384 |
| 동대구 | 2769875 |
| 오송 | 2181114 |
| 천안아산 | 2039345 |
| 수원 | 1731419 |
| 서울 | 1632729 |
| 천안 | 1445134 |
| 익산 | 1362569 |
| 평택 | 1353513 |
abrd_top = sum_abrd_by_stn.sort_values('ABRD_PRNB', ascending=False).head(10).index
abrd_top = abrd_top.tolist()
abrd_top
[‘서울’, ‘동대구’, ‘용산’, ‘대전’, ‘부산’, ‘수원’, ‘광명’, ‘영등포’, ‘오송’, ‘천안아산’]
공공데이터 추가
- 한국감정원 월별 KTX역 역세권 지가지수(2014년 11월 ~ 2019년 7월)
*지가지수 : 기준시점의 지수를 100으로 보았을 때, 기준시점 대비 가격상승분을 반영한 해당시점의 지수를 나타냄 - 각 역 단위 실 주소 및 위,경도
land_value = pd.read_csv(path+'land_value_2017_2019.csv', encoding='cp949')
land_value[['YYMM', '오송']].head()
| YYMM | 오송 | |
|---|---|---|
| 0 | 201701 | 100.226 |
| 1 | 201702 | 99.968 |
| 2 | 201703 | 100.988 |
| 3 | 201704 | 101.482 |
| 4 | 201705 | 102.830 |
#승차인원 상위 역 지가지수 변화 그래프
#land_value.set_index(land_value['YYMM'], inplace=True)
cols = ['YYMM'] + abrd_top
land_value_plt = land_value[cols]
land_value_plt['YYMM'] = land_value_plt['YYMM'].astype(str)
font = {'family' : 'nanumgothic', 'size':10}
plt.rc('font', **font) #font option
plt.rcParams["figure.figsize"] = (25,10)
land_value_plt.plot(x='YYMM', y=abrd_top)
plt.title('월별 역의 지가지수 흐름', fontsize=18)
plt.xlabel('Date', fontsize=18)
plt.ylabel('지가지수', fontsize=18)
plt.legend(fontsize=15, loc='best')
<matplotlib.axes._subplots.AxesSubplot at 0x7f16f307b2e8>
Text(0.5, 1.0, ‘월별 역의 지가지수 흐름’)
Text(0.5, 0, ‘Date’)
Text(0, 0.5, ‘지가지수’)
<matplotlib.legend.Legend at 0x7f16f30715f8>

stn_addr = pd.read_csv(path+'stn_addr_2016.csv', encoding='cp949')
stn_addr.head()
| 역명 | 주소 | |
|---|---|---|
| 0 | 가수원 | 대전 서구 가수원동 547-1 |
| 1 | 가야 | 부산 부산진구 백양대로 91 |
| 2 | 각계 | 충북 영동군 심천면 각계리 |
| 3 | 감곡 | 전북 정읍시 감곡면 유정리 196-1 |
| 4 | 강경 | 충남 논산시 강경읍 대흥리 32 |
#merge
ride_acvm_with_loc_addr = pd.merge(ride_acvm_with_loc, stn_addr, how='left', left_on='KOR_STOP_STN', right_on='역명')
ride_acvm_with_loc_addr.head()
| RUN_DT | STOP_STN | STLB_TRN_CLSF_CD | UP_DN_DV_CD | ABRD_PRNB | GOFF_PRNB | NSTP_PRNB | YYMM | KOR_STOP_STN | STN_NM | LAT | LNG | 역명 | 주소 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20191001 | 3900280 | 0 | D | 1148 | 3021 | 15849 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 |
| 1 | 20191001 | 3900280 | 7 | D | 630 | 1422 | 6902 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 |
| 2 | 20191001 | 3900280 | 10 | D | 49 | 127 | 615 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 |
| 3 | 20191001 | 3900023 | 7 | U | 19 | 4749 | 378 | 201910 | 서울 | 서울 | 37.554073 | 126.970702 | 서울 | 서울 용산구 동자동 43-205 |
| 4 | 20191001 | 3900096 | 7 | U | 1332 | 710 | 4545 | 201910 | 동대구 | 동대구 | 35.879437 | 128.628784 | 동대구 | 대구 동구 동대구로 550(신암동) |
지도 설정
- 좌표계 포맷 변경
- 역 별 위경도(WG84 -> UTM-K)
proj_UTMK = Proj(init='epsg:5178') # UTM-K(Bassel)
proj_WGS84 = Proj(init='epsg:4326') # Wgs84 경도/위도, GPS
def transform_w84_to_utmk(df):
return pd.Series(transform(proj_WGS84, proj_UTMK, df['LNG'], df['LAT']), index=['LNG', 'LAT'])
ride_acvm_with_loc_addr[['LNG_utmk', 'LAT_utmk']] = ride_acvm_with_loc_addr.apply(transform_w84_to_utmk, axis=1)
ride_acvm_with_loc_addr.head()
| Unnamed: 0 | RUN_DT | STOP_STN | STLB_TRN_CLSF_CD | UP_DN_DV_CD | ABRD_PRNB | GOFF_PRNB | NSTP_PRNB | YYMM | KOR_STOP_STN | STN_NM | LAT | LNG | 역명 | 주소 | LNG_utmk | LAT_utmk | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 20191001 | 3900280 | 0 | D | 1148 | 3021 | 15849 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 | 9.847740e+05 | 1.846622e+06 |
| 1 | 1 | 20191001 | 3900280 | 7 | D | 630 | 1422 | 6902 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 | 9.847740e+05 | 1.846622e+06 |
| 2 | 2 | 20191001 | 3900280 | 10 | D | 49 | 127 | 615 | 201910 | 오송 | 오송 | 36.620098 | 127.327582 | 오송 | 충청북도 청원군 강외면 봉산리 370-1 | 9.847740e+05 | 1.846622e+06 |
| 3 | 3 | 20191001 | 3900023 | 7 | U | 19 | 4749 | 378 | 201910 | 서울 | 서울 | 37.554073 | 126.970702 | 서울 | 서울 용산구 동자동 43-205 | 9.534382e+05 | 1.950351e+06 |
| 4 | 4 | 20191001 | 3900096 | 7 | U | 1332 | 710 | 4545 | 201910 | 동대구 | 동대구 | 35.879437 | 128.628784 | 동대구 | 대구 동구 동대구로 550(신암동) | 1.102084e+06 | 1.765044e+06 |
고속열차(KTX) 대상
- 승차,하차,통과인원수 0이거나 음수인 경우 제외
ride_acvm_with_loc_addr = ride_acvm_with_loc_addr[ride_acvm_with_loc_addr['STLB_TRN_CLSF_CD'] == 0]
ride_fin_df = ride_acvm_with_loc_addr[(ride_acvm_with_loc_addr[['ABRD_PRNB','GOFF_PRNB', 'NSTP_PRNB']] != 0).all(axis=1)]
ride_fin_df = ride_fin_df[['RUN_DT', 'STOP_STN', 'UP_DN_DV_CD', 'ABRD_PRNB', 'GOFF_PRNB', 'NSTP_PRNB','YYMM','KOR_STOP_STN', 'LNG_utmk', 'LAT_utmk']]
ride_fin_df_cols = ['운행년월일', '정차역코드', '상하행구분', '승차인원수', '하차인원수', '통과인원수', '운행년월','역명', 'LNG_utmk', 'LAT_utmk']
ride_fin_df.columns = ride_fin_df_cols
updown_dict = {'U':'상행', 'D':'하행'}
ride_fin_df['상하행구분'] = ride_fin_df['상하행구분'].map(updown_dict)
ride_fin_df.head()
| 운행년월일 | 정차역코드 | 상하행구분 | 승차인원수 | 하차인원수 | 통과인원수 | 운행년월 | 역명 | LNG_utmk | LAT_utmk | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20191001 | 3900280 | 하행 | 1148 | 3021 | 15849 | 201910 | 오송 | 9.847740e+05 | 1.846622e+06 |
| 6 | 20191001 | 3900047 | 하행 | 968 | 124 | 1819 | 201910 | 수원 | 9.558390e+05 | 1.918382e+06 |
| 12 | 20191001 | 3900685 | 하행 | 1 | 208 | 148 | 201910 | 창원 | 1.100874e+06 | 1.696025e+06 |
| 13 | 20191001 | 3900902 | 상행 | 980 | 17 | 1666 | 201910 | 창원중앙 | 1.109497e+06 | 1.694457e+06 |
| 16 | 20191001 | 3900229 | 상행 | 2269 | 72 | 3222 | 201910 | 광주송정 | 9.355993e+05 | 1.682427e+06 |
지도 및 차트 생성
- 해당 운행일자의 각 역 별 상-하행 구분에 따른 승차,하차,통과 인원 및 역의 지가지수 변동을 인터렉티브하게 표현함
widget_time = sorted(list(ride_fin_df['운행년월'].unique()))
widget_stn = list(ride_fin_df['역명'].unique())
widget_updown = ['하행', '상행']
widget_prnb_Value = ['승차인원수', '하차인원수', '통과인원수']
ride_acvm_gpd = gpd.GeoDataFrame(
ride_fin_df, geometry=gpd.points_from_xy(ride_fin_df.LNG_utmk, ride_fin_df.LAT_utmk)
)
ride_acvm_gpd.head()
| 운행년월일 | 정차역코드 | 상하행구분 | 승차인원수 | 하차인원수 | 통과인원수 | 운행년월 | 역명 | LNG_utmk | LAT_utmk | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20191001 | 3900280 | 하행 | 1148 | 3021 | 15849 | 201910 | 오송 | 9.847740e+05 | 1.846622e+06 | POINT (984774.029 1846622.323) |
| 6 | 20191001 | 3900047 | 하행 | 968 | 124 | 1819 | 201910 | 수원 | 9.558390e+05 | 1.918382e+06 | POINT (955838.951 1918382.084) |
| 12 | 20191001 | 3900685 | 하행 | 1 | 208 | 148 | 201910 | 창원 | 1.100874e+06 | 1.696025e+06 | POINT (1100874.105 1696025.006) |
| 13 | 20191001 | 3900902 | 상행 | 980 | 17 | 1666 | 201910 | 창원중앙 | 1.109497e+06 | 1.694457e+06 | POINT (1109496.880 1694456.908) |
| 16 | 20191001 | 3900229 | 상행 | 2269 | 72 | 3222 | 201910 | 광주송정 | 9.355993e+05 | 1.682427e+06 | POINT (935599.278 1682426.726) |
#base map loading
whole_map = pd.read_pickle(path+'whole_map.pkl')
whole_map.columns = ['geometry']
#b_time
w1 = widgets.Dropdown(
options=widget_time,
value=widget_time[0],
description='운행년월 :',
disabled=False,
)
#b_stn
w2 = widgets.Dropdown(
options=widget_stn,
value=widget_stn[0],
description='역명 :',
disabled=False,
)
#b_dir
w3 = widgets.Dropdown(
options=widget_updown,
value=widget_updown[0],
description='상하행 :',
disabled=False,
)
#want_view
w4 = widgets.Dropdown(
options=widget_prnb_Value,
value=widget_prnb_Value[0],
description='기준인원 :',
disabled=False,
)
def view(b_time = '', b_stn = '', b_dir = '', want_view = ''):
if b_time=='All':
return ride_acvm_gpd
temp_df = ride_acvm_gpd
temp_df = temp_df[temp_df['운행년월']==b_time]
temp_df = temp_df[temp_df['역명']==b_stn]
if temp_df.shape[0] == 0:
return "데이터가 없습니다"
font = {'family' : 'NanumGothic', 'size':10}
plt.rc('font', **font) #font option
fig = plt.figure(figsize=(28,8), constrained_layout=False)
gs = fig.add_gridspec(nrows=5, ncols=8, left=0.05, right=0.48, wspace=0.5)
ax1 = fig.add_subplot(gs[:5, :4]) #row, col
ax2 = fig.add_subplot(gs[:2, 4:8]) #row, col
ax3 = fig.add_subplot(gs[3:5, 4:8])
whole_map.plot(color='white', edgecolor='black', legend=True, ax=ax1, linewidth=0.2)
gpd.GeoDataFrame(temp_df).plot(column='역명', marker='*', color="r", markersize=40,legend=True, ax=ax1)
ax1.axes.get_xaxis().set_visible(False)
ax1.axes.get_yaxis().set_visible(False)
ax1.set_title('역 위치')
#1. 역명,기준연월, 상하행
df = temp_df[(temp_df['역명'] == b_stn) & (temp_df['상하행구분'] == b_dir)]
bar_1 = df[['운행년월일',want_view]]
bar_1.sort_index().plot.bar(x='운행년월일',y=want_view, ax=ax2, fontsize=10, color="orange", rot=90)
ax2.set_title('2019년 한달 간 기준인원 변화')
#2. 해당 역 지가지수
bar_2 = pd.DataFrame(land_value[['YYMM', b_stn]])
bar_2.sort_index().plot.bar(x='YYMM',y=b_stn, ax=ax3, fontsize=10, color="purple", rot=90)
ax3.set_ylim([80, 140])
ax3.set_title('17~19년 해당 역 지가지수 변화')
interact_manual(view, b_time=w1, b_stn=w2, b_dir=w3, want_view = w4)
#from IPython.display import Image
#Image('/home/yubin90/pyWork/diamond/widget_result.png')
<function main.view(b_time=‘’, b_stn=‘’, b_dir=‘’, want_view=‘’)>

서울시 거주자 인구이동 및 소비현황 시각화
분석 개요
- 목적: 서울시 거주자의 인구이동 및 소비현황 시각화를 하고자 함
분석 데이터
- 코리아크레딧뷰로(주)의 인구전입데이터
- 코리아크레딧뷰로(주)의 인구전출데이터
- 국토교통부의 시군구행정코드 및 경계지도 데이터(공공데이터)
분석 과정
1. R 패키지 로드 및 옵션 설정
R패키지 로드
options(scipen = 999) # full number
#load packages
library(data.table)
library(dplyr)
library(ggplot2)
#map 관련 라이브러리
library(ggmap) # 필요시 yum install libjpeg-devel
library(raster)
library(rgeos) # 필요시 yum install geos geos-devel
library(maptools)
library(rgdal) # 필요시 yum install gdal gdal-devel proj proj-devel
library(sp)
library(geosphere)
library(tibble)
#network 관련 라이브러리
library(igraph)
library(ggraph)
library(visNetwork)
knitr::opts_chunk$set(warning = FALSE, message=FALSE)
ggplot 관련 테마설정
my_theme <-
theme(
panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.title = element_text(hjust = 0.5, face = 'bold'),
legend.text = element_text(family = 'NanumGothic',
size = 8, face = 'bold'),
legend.title = element_text(family = 'NanumGothic',
size = 10, face = 'bold')
)
my_theme_bar <- theme(panel.background = element_blank(),
plot.title = element_text(hjust = 0.5, face = 'bold'),
axis.text.x = element_text(angle = 60, hjust = 1))
데이터 로드
data_path <- "/home/joohj7/analysis/project/2020_DT_교통예측시연"
# list.files(data_path, pattern = "csv")
MOVE_TYP1 <- fread(file.path(data_path, "TB_COL_KC_T023_MOVE_TYP1.csv"))
MOVE_TYP2 <- fread(file.path(data_path, "TB_COL_KC_T023_MOVE_TYP2.csv"))
시군구행정지도와 시군구코드 매핑
#시군구 데이터 매핑
siggfunc <- function(folder, layername) {
sigg_import <-
readOGR(
dsn = folder,
layer = layername,
encoding = 'CP949')
#좌표계 변환
to_crs = CRS("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs")
sigg <- spTransform(sigg_import, to_crs)
siggDF <- fortify(model = sigg)
sigg@data$id <- rownames(x=sigg@data)
# 이제 두 데이터프레임을 병합
siggDF <- merge(x= siggDF,
y=sigg@data[, c("id", 'SIG_KOR_NM',
"SIG_ENG_NM", "SIG_CD")],
by='id', all.x= TRUE)
# order를 10으로 나누었을 때 나머지가 1인 행만 남김(조밀도를 줄임)
siggDF <- siggDF[siggDF$order %% 10 == 1, ]
# 부속지역을 제외(조밀도를 줄임)
siggDF <- subset(x = siggDF, subset = siggDF$piece == 1)
# id와 order 기준으로 오름차순 정렬
siggDF <- siggDF[order(siggDF$id, siggDF$order), ]
return (siggDF)
}
sigg_df<- siggfunc(folder = '/home/joohj7/analysis/project/2020_DT_교통예측시연/SIG_201905',
layername = 'TL_SCCO_SIG')
## OGR data source with driver: ESRI Shapefile
## Source: "/home/joohj7/analysis/project/2020_DT_교통예측시연/SIG_201905", layer: "TL_SCCO_SIG"
## with 250 features
## It has 3 fields
head(sigg_df, 3)
| id | long | lat | order | hole | piece | group | SIG_KOR_NM | SIG_ENG_NM | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 127.0086 | 37.58047 | 1 | FALSE | 1 | 0.1 | 종로구 | Jongno-gu | |
| 11 | 0 | 127.0100 | 37.58028 | 11 | FALSE | 1 | 0.1 | 종로구 | Jongno-gu | |
| 21 | 0 | 127.0117 | 37.58151 | 21 | FALSE | 1 | 0.1 | 종로구 | Jongno-gu |
3 rows | 1-10 of 11 columns
2. 데이터 전처리
서울시 데이터 필터링
#지도에서 서울시만 추출
seoulDF<- sigg_df[substr(sigg_df$SIG_CD,1,2)==11,] #서울특별시:11
#지역이름의 유일이름 추출
area_df<- unique(sigg_df[, c("SIG_CD", "SIG_KOR_NM")])
head(area_df, 3)
| SIG_CD | SIG_KOR_NM | |
|---|---|---|
| 1 | 11110 | 종로구 |
| 2333 | 11140 | 중구 |
| 4251 | 11350 | 노원구 |
3 rows
#서울에서 서울로 옮긴경우
#전입데이터
SEOUL_MOVE_TYP1 <- MOVE_TYP1[MOVE_TYP1$PRV_CTNCD<=11740 &
MOVE_TYP1$CUR_CTNCD<=11740]
SEOUL_MOVE_TYP1 <- as.data.table(SEOUL_MOVE_TYP1)
head(SEOUL_MOVE_TYP1, 3)
| IRIS_KEY | IRIS_PARTITION <S3: integer64> | GB | BS_YR_MON | PRV_PVNCD | PRV_CTNCD | CUR_CTNCD | CUR_ADMCD | GENDER | AGE_BIN | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20191001000000 | 1 | 201910 | 11 | 11740 | 11215 | 11215860 | 1 | 60 | |
| 1 | 20191001000000 | 1 | 201910 | 11 | 11530 | 11500 | 11500530 | 1 | 20 | |
| 1 | 20191001000000 | 1 | 201910 | 11 | 11215 | 11260 | 11260520 | 1 | 30 |
3 rows | 1-10 of 17 columns
#전출데이터
MOVE_TYP2 <- MOVE_TYP2[IRIS_KEY==2017] #필터링
SEOUL_MOVE_TYP2 <- MOVE_TYP2[MOVE_TYP2$CUR_CTNCD<=11740 &
MOVE_TYP2$AFT_CTNCD<=11740]
SEOUL_MOVE_TYP2 <- as.data.table(SEOUL_MOVE_TYP2)
head(SEOUL_MOVE_TYP2, 3)
| IRIS_KEY | IRIS_PARTITION <S3: integer64> | GB | BS_YR_MON | CUR_BS_YR_MON | CUR_CTNCD | CUR_ADMCD | AFT_PVNCD | AFT_CTNCD | |
|---|---|---|---|---|---|---|---|---|---|
| 2017 | 20191001000000 | 2 | 201910 | 201710 | 11680 | 11680690 | 11 | 11650 | |
| 2017 | 20191001000000 | 2 | 201910 | 201710 | 11320 | 11320514 | 11 | 11170 | |
| 2017 | 20191001000000 | 2 | 201910 | 201710 | 11290 | 11290555 | 11 | 11650 |
3 rows | 1-9 of 18 columns
전입/전출 집계데이터 산출
#전입 집계
#지역구내 집계 통일
SEOUL_SUMM_TYP1 <- SEOUL_MOVE_TYP1 %>%
group_by(PRV_CTNCD, CUR_CTNCD, AGE_BIN) %>%
summarise_at(c("AVG_MON_INCOME", "MED_MON_INCOME","AVG_MON_CARDSPND"),
mean, na.rm=TRUE)
head(SEOUL_SUMM_TYP1, 3)
| PRV_CTNCD | CUR_CTNCD | AGE_BIN | AVG_MON_INCOME | MED_MON_INCOME | AVG_MON_CARDSPND |
|---|---|---|---|---|---|
| 11110 | 11110 | 20 | 1913.794 | 1796.235 | 860.4706 |
| 11110 | 11110 | 30 | 3213.735 | 2578.794 | 1429.9412 |
| 11110 | 11110 | 40 | 3579.118 | 3047.676 | 1782.8235 |
3 rows
#전출 집계
#지역구내 집계 통일
SEOUL_SUMM_TYP2 <- SEOUL_MOVE_TYP2 %>%
group_by(CUR_CTNCD, AFT_CTNCD, AGE_BIN) %>%
summarise_at(c("AVG_MON_INCOME", "MED_MON_INCOME","AVG_MON_CARDSPND"),
mean, na.rm=TRUE)
head(SEOUL_SUMM_TYP2, 3)
| CUR_CTNCD | AFT_CTNCD | AGE_BIN | AVG_MON_INCOME | MED_MON_INCOME | AVG_MON_CARDSPND |
|---|---|---|---|---|---|
| 11110 | 11110 | 20 | 1574.882 | 1502.471 | 707.7353 |
| 11110 | 11110 | 30 | 2587.676 | 2172.265 | 1323.1176 |
| 11110 | 11110 | 40 | 3142.941 | 2623.294 | 1642.7353 |
3 rows
전출지역 이름 매핑
#area center name point
center <- seoulDF %>% group_by(SIG_CD, SIG_KOR_NM) %>%
summarise_at(c("long", "lat"), function(x)(min(x)+(max(x)-min(x))/2))
center <- as.data.table(center)
#시군구 center label위치 세부조정 작업
center[SIG_KOR_NM=="서대문구"]$lat <- center[SIG_KOR_NM=="서대문구"]$lat -0.01
center[SIG_KOR_NM=="마포구"]$lat <- center[SIG_KOR_NM=="마포구"]$lat -0.005
center[SIG_KOR_NM=="종로구"]$lat <- center[SIG_KOR_NM=="종로구"]$lat -0.02
center[SIG_KOR_NM=="양천구"]$lat <- center[SIG_KOR_NM=="양천구"]$lat -0.01
center[SIG_KOR_NM=="강남구"]$lat <- center[SIG_KOR_NM=="강남구"]$lat -0.01
center[SIG_KOR_NM=="동대문구"]$lat <- center[SIG_KOR_NM=="동대문구"]$lat -0.005
center[SIG_KOR_NM=="동작구"]$lat <- center[SIG_KOR_NM=="동작구"]$lat +0.005
center[SIG_KOR_NM=="동작구"]$long <- center[SIG_KOR_NM=="동작구"]$long +0.005
center[SIG_KOR_NM=="서초구"]$long <- center[SIG_KOR_NM=="서초구"]$long -0.01
center[SIG_KOR_NM=="강북구"]$lat <- center[SIG_KOR_NM=="강북구"]$lat -0.01
center[SIG_KOR_NM=="성북구"]$lat <- center[SIG_KOR_NM=="성북구"]$lat -0.005
center[SIG_KOR_NM=="구로구"]$lat <- center[SIG_KOR_NM=="구로구"]$lat +0.001
#지역구 전출집계인구수
SEOUL_count <- SEOUL_MOVE_TYP2 %>% group_by(CUR_CTNCD, AFT_CTNCD) %>%
summarise_at("POP_CNT", sum, na.rm=TRUE)
head(SEOUL_count, 3)
| CUR_CTNCD | AFT_CTNCD | POP_CNT |
|---|---|---|
| 11110 | 11110 | 118628 |
| 11110 | 11140 | 467 |
| 11110 | 11170 | 498 |
3 rows
SEOUL_count <- merge(SEOUL_count, center,
by.x="CUR_CTNCD", by.y="SIG_CD", all.x=T)
SEOUL_count <- merge(SEOUL_count, center,
by.x="AFT_CTNCD", by.y="SIG_CD", all.x=T,
suffixes= c( ".CUR", ".AFT"))
SEOUL_count <- SEOUL_count[order(SEOUL_count$CUR_CTNCD, SEOUL_count$AFT_CTNCD), ]
# 그룹 id 계산하기
unique_mat<- unique(SEOUL_count[,c("CUR_CTNCD", "AFT_CTNCD")])
unique_mat$id <- rownames(unique_mat)
# id 매핑
SEOUL_count <- merge(SEOUL_count, unique_mat,
by=c("AFT_CTNCD", "CUR_CTNCD"))
SEOUL_count <- as.data.table(SEOUL_count)
3. 분석데이터 시각화
3.1. 서울시 인구전출 데이터 분석
지역구 전출 빈도수 (구역내&타지역포함)
# 지역구 전출 빈도수
MOVE_COUNT<- SEOUL_count%>% group_by(SIG_KOR_NM.CUR) %>%
summarise(count = sum(POP_CNT))%>%
arrange(desc(count))
head(MOVE_COUNT, 3)
| SIG_KOR_NM.CUR | count |
|---|---|
| 송파구 | 479132 |
| 강남구 | 435717 |
| 강서구 | 421715 |
3 rows
# 지역구 전출 코드 매핑
MOVE_COUNT_map <- merge(seoulDF, MOVE_COUNT,
by.x="SIG_KOR_NM", by.y='SIG_KOR_NM.CUR')
MOVE_COUNT_map <- MOVE_COUNT_map[order(MOVE_COUNT_map$id, MOVE_COUNT_map$order),]
MOVE_COUNT_map <- as.data.table(MOVE_COUNT_map)
head(MOVE_COUNT_map, 3)
| SIG_KOR_NM | id | long | lat | order | hole | piece | group | SIG_ENG_NM | SIG_CD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 종로구 | 0 | 127.0086 | 37.58047 | 1 | FALSE | 1 | 0.1 | Jongno-gu | 11110 | |
| 종로구 | 0 | 127.0100 | 37.58028 | 11 | FALSE | 1 | 0.1 | Jongno-gu | 11110 | |
| 종로구 | 0 | 127.0117 | 37.58151 | 21 | FALSE | 1 | 0.1 | Jongno-gu | 11110 |
3 rows | 1-10 of 11 columns
전체 전출 빈도수(barplot)
# 서울시 지역구 인구 전출 빈도수
ggplot(data = MOVE_COUNT, aes(x=reorder(SIG_KOR_NM.CUR, -count), y=count)) +
geom_bar(stat="identity",fill="purple", alpha=0.5)+ labs(x="지역", y="빈도수")+
scale_y_continuous(limits = c(0, 600000),
breaks = seq(0, 600000, by = 200000))+
my_theme_bar + ggtitle("서울시 지역구 인구 전출 빈도수")

#전체 전출을 빈번하게 하는 지도
ggplot(data = MOVE_COUNT_map,
mapping = aes(x = long, y = lat)) +
geom_polygon(aes(group= group, fill= count),color = 'black') +
geom_text(data= center, aes(x=long, y=lat, label=SIG_KOR_NM), size=3)+
scale_fill_gradient(low = 'white', high = 'red') +
coord_fixed() + my_theme + ggtitle("서울시 지역구 인구 전출 빈도수")

지역구 전출 빈도수
#전체 전출을 빈번하게 하는 지도
MOVE_COUNT2<- SEOUL_count%>% group_by(SIG_KOR_NM.CUR) %>%
filter(SIG_KOR_NM.CUR!=SIG_KOR_NM.AFT)%>% summarise(count = sum(POP_CNT)) %>%
arrange(desc(count))
MOVE_COUNT_map2 <- merge(seoulDF, MOVE_COUNT2,
by.x="SIG_KOR_NM", by.y='SIG_KOR_NM.CUR')
MOVE_COUNT_map2 <- MOVE_COUNT_map2[order(MOVE_COUNT_map2$id, MOVE_COUNT_map2$order),]
MOVE_COUNT_map2 <- as.data.table(MOVE_COUNT_map2)
#서울내 타지역으로의 빈도수(barplot)
ggplot(data = MOVE_COUNT2, aes(x=reorder(SIG_KOR_NM.CUR, -count), y=count)) +
geom_bar(stat="identity",fill="purple", alpha=0.5)+ labs(x="지역", y="빈도수")+
scale_y_continuous(limits = c(0, 60000),
breaks = seq(0, 60000, by = 20000))+
my_theme_bar + ggtitle("서울시 지역구 전출 빈도수")
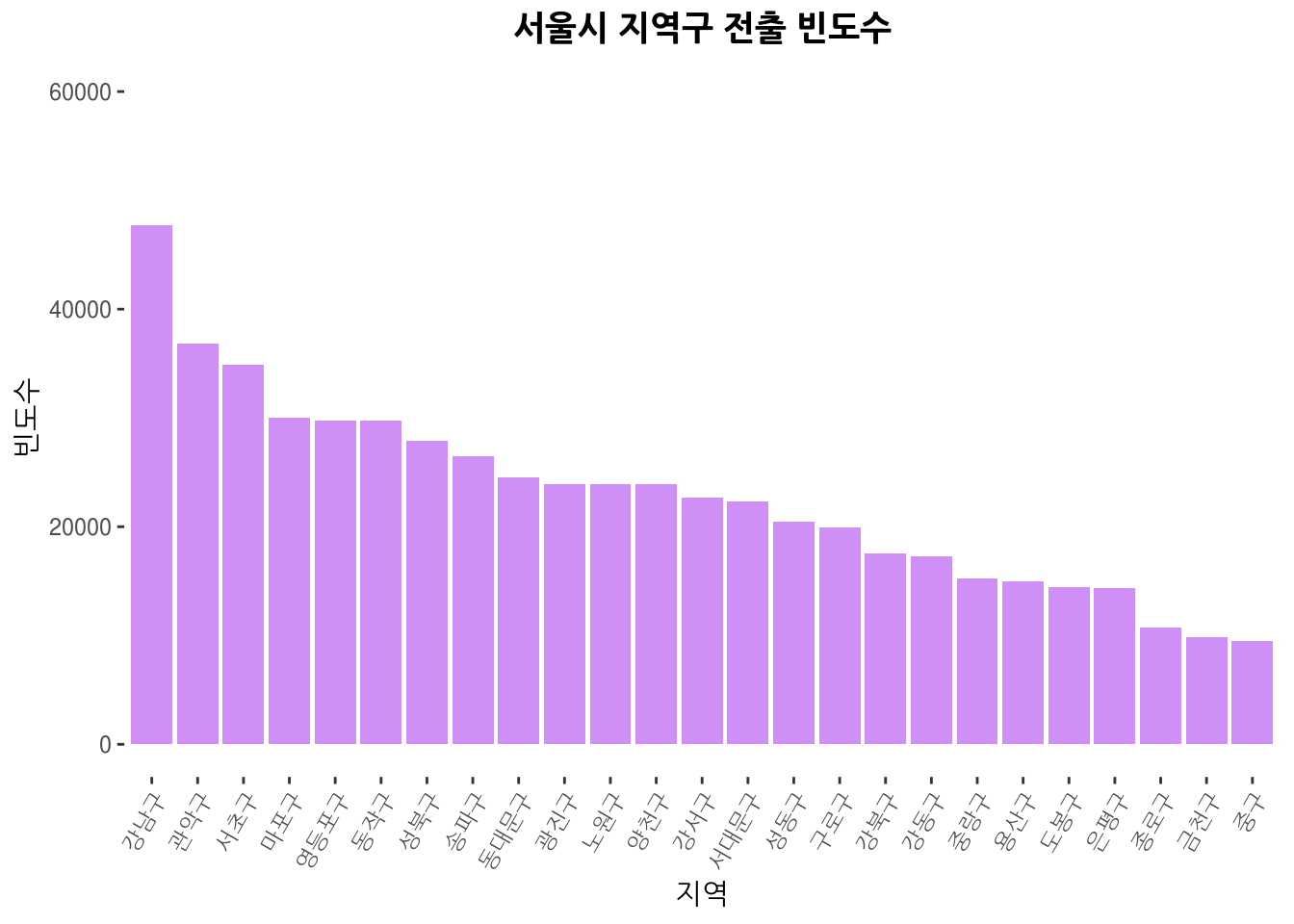
ggplot(data = MOVE_COUNT_map2,
mapping = aes(x = long, y = lat)) +
geom_polygon(aes(group= group, fill= count),color = 'black') +
geom_text(data= center, aes(x=long, y=lat, label=SIG_KOR_NM), size=3)+
scale_fill_gradient(low = 'white', high = 'red') +
coord_fixed() + my_theme + ggtitle("서울시 지역구 전출 빈도수")

-
전입 전출 데이터는 2년기준.
-
한강 이남간의 전출이 활발한편
-
첫째로 자기 지역(구)에서 전출하여 자기 지역(구)로 전입하는경우가 항상 첫번째.(10만 단위 -> 만 단위로)
-
서울내 전출 자체는 송파구>강남구>강서구>관악구>노원구 순으로 나오나
-
서울내 타지역으로의 전출만을 집계하면 강남구>관악구>서초구>마포구>영등포구 순
-
전체 전출에 비해 송파구, 강서구, 노원구의 경우 타 지역으로의 전출이 많지 않은편
-
종로구,중구, 금천구의 경우 전출인구가 많지 않은 지역
3.2. 서울거주자 인구 전출의 이동량 상위 5지역
#인구 전출 이동량이 높은 지역 산출
MOVE_COUNT2_detail <- SEOUL_count%>%
group_by(SIG_KOR_NM.CUR, SIG_KOR_NM.AFT) %>%
filter(SIG_KOR_NM.CUR!=SIG_KOR_NM.AFT)%>%
summarise(count = sum(POP_CNT)) %>%
arrange(desc(count))
MOVE_COUNT2_detail
| SIG_KOR_NM.CUR | SIG_KOR_NM.AFT | count |
|---|---|---|
| 강남구 | 송파구 | 11318 |
| 양천구 | 강서구 | 10006 |
| 강남구 | 서초구 | 9497 |
| 서초구 | 강남구 | 8687 |
| 강서구 | 양천구 | 8321 |
| 강동구 | 송파구 | 8182 |
| 송파구 | 강동구 | 7508 |
| 서대문구 | 은평구 | 7156 |
| 서초구 | 동작구 | 6760 |
| 관악구 | 동작구 | 6607 |
Next
123456
…
60
Previous
1-10 of 597 rows
둘째로 자기 지역(구)에서 타 지역(구)로 전출하는 경우의 순서는 1_강남구->송파구, 2_양천구->강서구, 3_강남구->서초구, 4_서초구->강남구, 5_강서구->양천구 순
서울시 내 지역구별 전출인구의 지도 매핑작업
SEO.MAP_AFT <- merge(seoulDF, SEOUL_count, by.x="SIG_CD", by.y='AFT_CTNCD')
SEO.MAP_AFT <- SEO.MAP_AFT[order(SEO.MAP_AFT$id.x, SEO.MAP_AFT$order),]
SEO.MAP_AFT <- as.data.table(SEO.MAP_AFT)
#서울시 내 지역구별 전출인구의 시각화 함수
area.out.plot<- function(area){
plt<- ggplot(data = SEO.MAP_AFT,
mapping = aes(x = long, y = lat)) +
geom_polygon(aes(group= group), fill= "white",color = 'black') +
geom_polygon(data = SEO.MAP_AFT[SIG_KOR_NM.CUR==area&SIG_KOR_NM.AFT==area],
aes(group= group), fill= "gray",color = 'black')+
geom_polygon(data = SEO.MAP_AFT[SIG_KOR_NM.CUR==area &SIG_KOR_NM.AFT!=area],
aes(group= group, fill= POP_CNT),color = 'black') +
geom_text(data= center, aes(x=long, y=lat, label=SIG_KOR_NM), size=3)+
geom_segment(data = SEOUL_count[SIG_KOR_NM.CUR==area&SIG_KOR_NM.AFT!=area] %>%
group_by(AFT_CTNCD) %>%
arrange(desc(POP_CNT))%>% head(5),
aes(x = long.CUR, y = lat.CUR,
xend = long.AFT, yend = lat.AFT),
color = "darkgreen", size = 0.5,
alpha = 0.8, lineend = "round",
arrow = arrow(length = unit(0.02, "npc")))+
scale_fill_gradient(low = 'white', high = 'red') +
coord_fixed() + my_theme
return(plt)
}
지역구별 전출 상위 5지역 지도시각화
# 강남구 인구 전출 지도
area.out.plot("강남구")

# 양천구 인구 전출 지도
area.out.plot("양천구")

# 서초구 인구 전출 지도
area.out.plot("서초구")

# 강서구 인구 전출 지도
area.out.plot("강서구")

# 송파구 인구 전출 지도
area.out.plot("송파구")

3.3. 전출 네트워크 분석
MOVE_COUNT2_detail$count <- ifelse(MOVE_COUNT2_detail$count/100<10,
NA, MOVE_COUNT2_detail$count)
MOVE_COUNT2_detail<- na.omit(MOVE_COUNT2_detail)
SIG_KOR_NM.CUR <- SEOUL_count %>%
distinct(SIG_KOR_NM.CUR) %>%
rename(label = SIG_KOR_NM.CUR)
SIG_KOR_NM.AFT <- SEOUL_count %>%
distinct(SIG_KOR_NM.AFT) %>%
rename(label = SIG_KOR_NM.AFT)
# 노드 생성 작업
nodes <- full_join(SIG_KOR_NM.CUR, SIG_KOR_NM.AFT, by = "label")
nodes <- nodes %>% rowid_to_column("id")
nodes$shape <- "circle"
# 엣지 생성 작업
edges <- MOVE_COUNT2_detail %>%
left_join(nodes, by = c("SIG_KOR_NM.CUR" = "label")) %>%
rename(from = id)
edges <- edges %>%
left_join(nodes, by = c("SIG_KOR_NM.AFT" = "label")) %>%
rename(to = id)
edges <- edges[, c("from", "to", "count")]
edges <- mutate(edges, width = round(count/10000,1)*10)
서울시 지역구 전입/전출 연관 네트워크
visNetwork(nodes, edges) %>%
visIgraphLayout(layout = "layout_with_fr") %>%
visEdges(arrows = "middle")

- 강남,송파,서초 /노원,성북,강북,중랑/광진,동대문,성동/관악,동작,마포, 영등포/ 서대문,은평,종로 등의 5가지 집단내에서 주로 이동.
- 일부지역구 (중구)는 전출이 활발한 편은 아님
3.4. 서울시 연령별 지역구 전출
#지역으로 전출
AGE_MOVE <- SEOUL_MOVE_TYP2%>% group_by(AFT_CTNCD, AGE_BIN) %>%
summarise(count = sum(POP_CNT))
AGE_MOVE <- merge(AGE_MOVE, area_df, by.x="AFT_CTNCD", by.y="SIG_CD",
all=T)
AGE_MOVE <- as.data.table(AGE_MOVE)
AGE_MOVE <- AGE_MOVE[substr(AFT_CTNCD,1,2)==11, ]
AGE_MOVE%>% group_by(AGE_BIN, AFT_CTNCD) %>%
arrange(AGE_BIN, desc(count))
| AFT_CTNCD | AGE_BIN | count | SIG_KOR_NM |
|---|---|---|---|
| 11710 | 20 | 93974 | 송파구 |
| 11620 | 20 | 91364 | 관악구 |
| 11500 | 20 | 83038 | 강서구 |
| 11680 | 20 | 82750 | 강남구 |
| 11290 | 20 | 77560 | 성북구 |
| 11350 | 20 | 77081 | 노원구 |
| 11230 | 20 | 68836 | 동대문구 |
| 11590 | 20 | 65388 | 동작구 |
| 11470 | 20 | 63370 | 양천구 |
| 11380 | 20 | 62790 | 은평구 |
Next
123456
…
15
Previous
1-10 of 150 rows
# 서울시 지역구 전출인구 데이터 집계
AGE_MOVE2 <- SEOUL_MOVE_TYP2%>% group_by(CUR_CTNCD, AFT_CTNCD, AGE_BIN) %>%
filter(CUR_CTNCD!=AFT_CTNCD)%>%
summarise(count = sum(POP_CNT))
AGE_MOVE2 <- merge(AGE_MOVE2, area_df, by.x="AFT_CTNCD", by.y="SIG_CD",
all=T)
AGE_MOVE2 <- merge(AGE_MOVE2, area_df, by.x="CUR_CTNCD", by.y="SIG_CD",
all=T, suffixes = c(".AFT", ".CUR"))
AGE_MOVE2 <- as.data.table(AGE_MOVE2)
AGE_MOVE2 <- AGE_MOVE2[substr(AGE_MOVE2$CUR_CTNCD,1,2)==11&
substr(AGE_MOVE2$AFT_CTNCD,1,2)==11, ]
AGE_MOVE2 <- AGE_MOVE2%>% group_by(AGE_BIN, AFT_CTNCD) %>%
arrange(AGE_BIN, desc(count))
AGE_MOVE2 <- as.data.table(AGE_MOVE2)
- 연령별 지역구 전출 네트워크 전처리
- 전출 1000이상의 데이터만 집계
- 관계를 명확히 보기위해 데이터에 가중치를 줌
연령별 지역구 네트워크
##### 연령별 지역구 네트워크 함수
age_net <- function(age){
AGE_NM.CUR <- AGE_MOVE2[,c("SIG_KOR_NM.CUR")] %>%
distinct(SIG_KOR_NM.CUR) %>%
rename(label = SIG_KOR_NM.CUR)
AGE_NM.AFT <- AGE_MOVE2[,c("SIG_KOR_NM.AFT")] %>%
distinct(SIG_KOR_NM.AFT) %>%
rename(label = SIG_KOR_NM.AFT)
AGE_nodes <- full_join(SIG_KOR_NM.CUR, SIG_KOR_NM.AFT, by = "label")
AGE_nodes <- AGE_nodes %>% rowid_to_column("id")
AGE_nodes$shape <- "circle"
AGE_edges <- AGE_MOVE2[AGE_BIN==age] %>%
filter(count>1000)%>%
left_join(AGE_nodes, by = c("SIG_KOR_NM.CUR" = "label")) %>%
rename(from = id)
AGE_edges <- AGE_edges %>%
left_join(AGE_nodes, by = c("SIG_KOR_NM.AFT" = "label")) %>%
rename(to = id)
AGE_edges <- AGE_edges[, c("from", "to", "count")]
AGE_edges <- mutate(AGE_edges, width = round(count/1000)*5)
vis <- visNetwork(AGE_nodes, AGE_edges) %>%
visIgraphLayout(layout = "layout_with_fr") %>%
visEdges(arrows = "middle")
return(vis)
}
# 20대 인구 전출 네트워크
age_net(20)

# 30대 인구 전출 네트워크
age_net(30)

# 40대 인구 전출 네트워크
age_net(40)

# 50대 인구 전출 네트워크
age_net(50)

- 20~30대에서는 활발하던 인구이동이 4-50대 이상으로 갈수록 지역구를 잘 벗어나지 않는 특성을 보임
3.5. 서울시 지역구 전입/전출비율
#전입 데이터 서울시 지역구별 집계인구
IN_CTNCD_POP <- SEOUL_MOVE_TYP1 %>%
group_by(CUR_CTNCD) %>%
filter(PRV_CTNCD!=CUR_CTNCD)%>%
summarise_at("POP_CNT", sum, na.rm=TRUE)
#전출 데이터 서울시 지역구별 집계인구
OUT_CTNCD_POP <- SEOUL_MOVE_TYP2 %>%
group_by(CUR_CTNCD) %>%
filter(CUR_CTNCD!=AFT_CTNCD)%>%
summarise_at("POP_CNT", sum, na.rm=TRUE)
#전입/전출 데이터를 현재 지역구 기준으로 병합
INOUT_CTNCD_POP<- merge(IN_CTNCD_POP,
OUT_CTNCD_POP,
by=c("CUR_CTNCD"),
suffixes=c(".MV_TYP1", ".MV_TYP2"))
INOUT_CTNCD_POP <- merge(INOUT_CTNCD_POP, area_df,
by.x="CUR_CTNCD", by.y="SIG_CD")
INOUT_CTNCD_POP <- as.data.table(INOUT_CTNCD_POP)
#전입-전출의 차이를 계산
INOUT_CTNCD_POP$MV_DIFF<- INOUT_CTNCD_POP$POP_CNT.MV_TYP1 -
INOUT_CTNCD_POP$POP_CNT.MV_TYP2
#전입-전출의 차의 증감 상태를 산출
INOUT_CTNCD_POP$status <- factor(ifelse(INOUT_CTNCD_POP$MV_DIFF<0, "감소", "증가"))
INOUT_CTNCD_POP
| CUR_CTNCD | POP_CNT.MV_TYP1 | POP_CNT.MV_TYP2 | SIG_KOR_NM | MV_DIFF | status |
|---|---|---|---|---|---|
| 11110 | 8764 | 10771 | 종로구 | -2007 | 감소 |
| 11140 | 7928 | 9483 | 중구 | -1555 | 감소 |
| 11170 | 15299 | 14996 | 용산구 | 303 | 증가 |
| 11200 | 23974 | 20474 | 성동구 | 3500 | 증가 |
| 11215 | 23541 | 23941 | 광진구 | -400 | 감소 |
| 11230 | 21752 | 24577 | 동대문구 | -2825 | 감소 |
| 11260 | 19967 | 15211 | 중랑구 | 4756 | 증가 |
| 11290 | 23737 | 27918 | 성북구 | -4181 | 감소 |
| 11305 | 16521 | 17564 | 강북구 | -1043 | 감소 |
| 11320 | 15278 | 14421 | 도봉구 | 857 | 증가 |
Next
123
Previous
1-10 of 25 rows
지역구 전입/전출 현황

지역구 전입/전출 현황(지도)

- 지역구 내로의 전입/전출 제외
- 송파구>은평구>강서구의 순으로 전입 인구수가 상승세
- 강남구>서초구>성북구 순으로 전출 인구수가 감소세
3.6. 서울시 연령별 소득 및 소비 현황
#현재 지역구의 평균월소득, 중위월소득, 평균신용카드소비 재집계
SEOUL_CUR_INCOME<- SEOUL_SUMM_TYP2 %>%
group_by(CUR_CTNCD, AGE_BIN) %>%
summarise_at(c("AVG_MON_INCOME", "MED_MON_INCOME","AVG_MON_CARDSPND"),
mean, na.rm=TRUE)
#현재의 사용자 시군구 코드 병합
SEOUL_CUR_INCOME <- merge(seoulDF, SEOUL_CUR_INCOME,
by.x="SIG_CD", by.y="CUR_CTNCD", all.x=T)
SEOUL_CUR_INCOME <- SEOUL_CUR_INCOME[order(SEOUL_CUR_INCOME$id,
SEOUL_CUR_INCOME$order), ]
SEOUL_CUR_INCOME <- as.data.table(SEOUL_CUR_INCOME)
#천단위 -> 만단위로 단위 조정
SEOUL_CUR_INCOME$AVG_MON_INCOME <- SEOUL_CUR_INCOME$AVG_MON_INCOME/10
SEOUL_CUR_INCOME$MED_MON_INCOME <- SEOUL_CUR_INCOME$MED_MON_INCOME/10
SEOUL_CUR_INCOME$AVG_MON_CARDSPND <- SEOUL_CUR_INCOME$AVG_MON_CARDSPND/10
서울시 지역구내 월별 중위소득집계
SEOUL_CUR_INCOME$AGE_BIN <- factor(SEOUL_CUR_INCOME$AGE_BIN)
levels(SEOUL_CUR_INCOME$AGE_BIN) <- paste0("AGE = ", levels(SEOUL_CUR_INCOME$AGE_BIN))
ggplot(data = SEOUL_CUR_INCOME ,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(mapping = aes(fill =MED_MON_INCOME),
color = 'black') +
#theme_bw() +
coord_fixed() +
scale_fill_gradient(low = 'white', high = 'red') +
facet_wrap(~AGE_BIN) + my_theme

- 20-30대 까지는 지역별 소득 편차가 있지 않은편, 연령이 증가할수록 편차 발생
- 소득의 경우 극단값의 영향이 크므로 중위수의 값으로 산출
- 20대에는 가장 낮은 월소득, 30-50대에 안정적인 소득 분포, 60-70대에는 거의 낮은 소득
- 40-50대에 강남,서초,송파,양천,노원 등 일부 지역이 월별 고소득자 분포
서울시 지역구내 월별 신용카드 소비 분석
ggplot(data = SEOUL_CUR_INCOME ,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(mapping = aes(fill =AVG_MON_CARDSPND),
color = 'black') +
#theme_bw() +
coord_fixed() +
scale_fill_gradient(low = 'white', high = 'red') +
facet_wrap(~AGE_BIN)+ my_theme

- 20대에는 낮은 소득에 비해 신용카드소비량이 다소 높음.